The Illusion of Edge AI Readiness¶
The Rise of Edge AI¶
Edge AI is no longer experimental.
In recent years, running machine learning models directly on devices has moved from research into reality. Microcontrollers — once limited to simple control logic — are now capable of executing inference workloads locally, without relying on continuous cloud connectivity.
This shift is not driven by hype. It is driven by necessity.
Latency requirements, bandwidth limitations, privacy concerns, and cost pressures are all pushing computation closer to where data is generated. Instead of sending raw data to the cloud, devices can now process it in real time — on site, in context, and within strict operational constraints.
As a result, Edge AI is rapidly being adopted across industries:
- in aviation, systems analyze operational data directly at the airport edge,
- in manufacturing, machines make real-time decisions on the factory floor,
- in infrastructure, distributed devices monitor and respond without centralized control
The tooling ecosystem has evolved alongside this demand. Frameworks for model optimization, quantization, and deployment on constrained hardware have matured significantly. What once required specialized expertise is now increasingly accessible to development teams.
From a technical perspective, the barrier to entry has been lowered.
Today, it is entirely feasible to take a trained model, compress it, and run inference on a microcontroller with limited memory and processing power. For many teams, this moment — the first successful inference running on-device — marks a milestone. It feels like the problem has been solved — but this moment can be misleading.
Getting a model to run on a device is only the beginning — not the end.
The "It Works" Trap¶
For many teams, the defining moment in an Edge AI project is simple:
The model runs on the device.
After weeks or months of development — training, optimizing, compressing — the system finally executes inference on a microcontroller. Inputs are processed. Outputs are produced. The pipeline works.
It is a genuine achievement — it creates a powerful sense of progress.
At this point, it is natural to assume that the hardest part is behind you. The model is functional, performance is acceptable, and the device behaves as expected under controlled conditions.
From a technical perspective, the objective appears to be met, but this is where many projects begin to drift. What has been proven is not a deployable system — it is a working demonstration.
The distinction is subtle — but critical. A demonstration answers a narrow question:
Can this model run on this device?
A production system must answer far more complex ones:
- can this model be updated after deployment?
- can thousands of devices be managed consistently?
- can failures be detected and resolved remotely?
- can security vulnerabilities be addressed without physical access?
In most projects, these questions are not answered at the moment of first success.
They are postponed. The system is validated in isolation — on a bench, in a lab, or within a limited pilot. Connectivity is stable, access is immediate, conditions are predictable — reality is none of these things.
Once devices leave controlled environments, they become part of a distributed system. They operate under constraints, variability, and uncertainty. They are expected to evolve over time — without direct human intervention.
This is where the gap begins to appear.
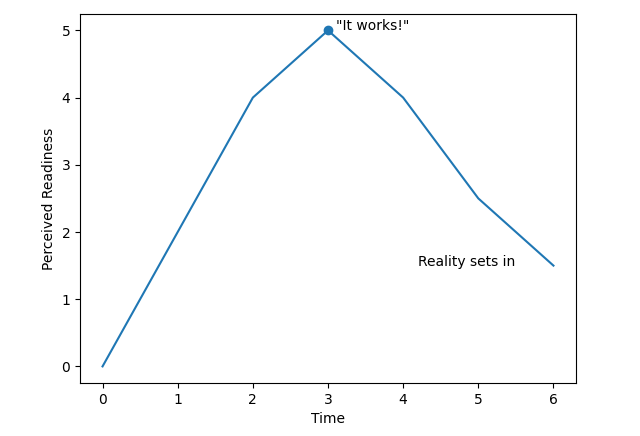
Figure 1: Perceived Readiness Over Time
A system that works once is fundamentally different from a system that must work continuously, adapt, and be maintained over years. The model may be ready — the system is not. The difference becomes clear when comparing a working prototype to a production system:
| Prototype | Production |
|---|---|
| Runs once | Runs continuously |
| Local test environment | Distributed system |
| Manual control | Remote fleet management |
| Static behavior | Continuous evolution |
| Known conditions | Unpredictable environments |
| Direct access | Limited or no physical access |
The Constraints of Microcontrollers¶
Edge AI does not run in the cloud — it runs on devices that were never designed to behave like it. Microcontrollers are fundamentally different from the systems most software is built for.
They operate with strict limitations — not edge cases, but as defining characteristics.
Memory is measured in kilobytes or a few megabytes, not gigabytes. Processing power is limited and often shared across multiple responsibilities. Power consumption must be tightly controlled, sometimes down to microamp levels.
There is no operating system in the traditional sense — no containerization, no abstraction layers to hide complexity — what runs on the device is often everything the device can support. This has direct consequences.
There is no built-in infrastructure for:
- managing software versions,
- updating logic after deployment,
- monitoring system behavior over time,
- handling failure states gracefully
Each of these capabilities — taken for granted in cloud or server environments — must be explicitly designed, implemented, and maintained within severe constraints.
Connectivity adds another layer of complexity. Devices may operate on unstable networks, experience long periods offline, or depend on low-bandwidth communication channels. In many cases, physical access is impractical or impossible once deployed.
A device installed in an airport, a factory floor, or a remote location is not something that can be easily retrieved, inspected, or manually updated. It must operate independently — and it must continue to operate reliably over long periods of time.
This changes the nature of the problem.
You are no longer building an application that runs in a controlled environment. You are building a system that must survive in the real world — under constraints, variability, and limited control.
The success of such a system is not determined by whether it runs. It is determined by whether it can continue to run, adapt, and be trusted — without direct intervention. That requires more than just a working model.
The Missing Infrastructure Layer¶
In cloud environments, lifecycle management is assumed.
Applications are deployed through pipelines. Updates are continuous. Monitoring, logging, and rollback mechanisms are built into the platform. These capabilities are not treated as features — they are part of the foundation.
At the edge, this foundation does not exist.
Microcontroller-based systems typically operate without any native support for managing software over time. Once deployed, they are often treated as static units — programmed once, expected to run indefinitely.
There is no standard layer responsible for:
- securely provisioning devices with identity and trust,
- deploying and updating software or AI models remotely,
- monitoring behavior across a fleet of devices,
- detecting anomalies or failures in real time,
- rolling back changes when something goes wrong
Each of these capabilities must be built from scratch — or not built at all.
In many cases, they are deferred.
Early deployments prioritize getting functionality onto the device. The system is validated in controlled environments, where manual access and direct intervention are still possible.
As deployments scale, this approach begins to break down. Without a dedicated infrastructure layer, every device becomes an isolated system. Updates require manual processes. Visibility is limited. Security is reactive rather than controlled. The complexity does not grow linearly — it compounds.
Managing ten devices manually may be feasible — managing thousands is not.
At this point, teams are forced to address problems that were never part of the original design:
- how do we update models across all devices consistently?
- how do we verify that updates were applied correctly?
- how do we respond to vulnerabilities discovered after deployment?
- how do we maintain trust in systems we cannot directly access?
These are not edge cases.
They are fundamental requirements of any production system. Yet, in most Edge AI architectures, there is no built-in mechanism to address them. The result is a structural gap. Not in compute, not in models, but in the ability to manage what has been deployed.
The AI Deployment Blind Spot¶
The rapid progress of Edge AI has been driven by a clear focus:
Building better models.
Across the industry, teams are optimizing for accuracy, performance, and efficiency. Models are trained, compressed, and adapted to run within increasingly tight constraints. Tool chains have evolved to support quantization, pruning, and deployment on microcontrollers.
This focus is both necessary and valuable.
Without it, Edge AI would not be possible — but it also shapes how problems are defined. When the primary objective is to make models run efficiently on constrained hardware, success is measured at the level of inference:
- does the model fit within memory constraints?
- does it meet latency requirements?
- does it produce acceptable results?
These are important questions — but they are not sufficient. They address the behavior of a model in isolation — not the behavior of a system over time.
Lifecycle considerations — how software is deployed, updated, monitored, and secured — exist outside the immediate scope of model development. They are often treated as downstream concerns, to be addressed later in the process.
In many cases, “later” becomes “never fully resolved.”
This is not a failure of AI teams — it is a natural consequence of specialization.
AI vendors focus on advancing model capabilities. Hardware providers focus on performance and efficiency. Connectivity providers focus on moving data. Each layer evolves independently.
What remains unaddressed is the space between them. The responsibility for managing deployed systems — ensuring that devices can be updated, secured, and controlled over time — does not clearly belong to any single layer.
As a result, it is often fragmented, improvised, or overlooked entirely.
The system works, but it lacks cohesion — without cohesion, it lacks control. This is the blind spot, not in how models are built — but in how they are expected to live, evolve, and be maintained once deployed.
When Edge AI Meets the Real World¶
Edge AI systems are not deployed in isolation.
They operate within real environments — complex, dynamic, and often unforgiving. Airports, factories, logistics hubs, and infrastructure systems are not controlled test settings. They are live operations, where reliability is expected and failure has consequences.
In these environments, devices are distributed across physical locations. They may be difficult to access, they are expected to operate continuously, and once deployed, they become part of a larger system that must function as a whole.
Consider what happens over time.
A model that performs well today may require adjustment tomorrow. New data patterns emerge, conditions change, performance degrades — without the ability to update the model remotely, the system begins to diverge from reality.
Now consider security.
A vulnerability is discovered in a deployed component. The issue is known. A fix exists — but the devices are already in the field. Without a mechanism to apply updates at scale, the system remains exposed — not because the problem cannot be solved, but because it cannot be addressed operationally.
Then consider failure.
A subset of devices begins behaving unexpectedly, outputs are inconsistent, performance drops. Without visibility into what is happening across the fleet, diagnosing the issue becomes slow and uncertain. Each device becomes a potential point of failure, with limited insight and limited control.
These are not hypothetical scenarios.
They are the natural result of deploying intelligent systems into environments where conditions evolve, and direct access is limited.
In aviation environments such as those operated by SAS Scandinavian Airlines at Stockholm Arlanda Airport, or in industrial settings supported by companies like Comau, systems are expected to operate reliably over long periods, under changing conditions, and at scale.
In these contexts, a working model is only a starting point. What matters is whether the system can be maintained, adapted, and trusted over time. Once deployed, the question is no longer:
Does it work?
It becomes:
Can we control it?
The Edge Lifecycle Gap¶
Across Edge AI deployments, a consistent pattern emerges.
The models work. The devices operate. But the systems cannot be managed. What is missing is not computational capability. It is not model performance. It is the ability to control what happens after deployment.
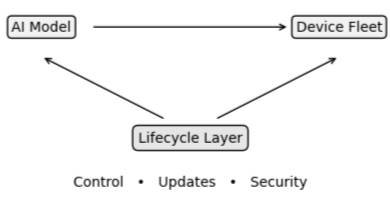
Figure 2: The Missing Layer
A system that works once is fundamentally different from a system that must work continuously, adapt, and be maintained over years. This is the Edge Lifecycle Gap. It is the gap between:
- a system that can run inference,
- a system that can be deployed, maintained, secured, and evolved over time
In cloud environments, this gap is largely invisible. Lifecycle management is embedded into the platform. Systems are designed to be updated continuously, monitored centrally, and controlled at scale.
At the edge, this layer is absent. Devices are deployed into the field with limited mechanisms for change, updates are difficult or inconsistent, visibility is partial, and control is fragmented. As a result, systems become static in environments that are inherently dynamic. This creates a fundamental mismatch — the world changes, the system does not.
Over time, this leads to:
- degradation in model performance,
- increased operational overhead,
- exposure to unresolved vulnerabilities,
- loss of trust in deployed systems
None of these issues are caused by the model itself — they are caused by the absence of lifecycle management.
This is why many Edge AI initiatives struggle to move beyond pilot stages. The initial technical success — running inference on a device — does not translate into a system that can operate reliably at scale.
The problem is not whether Edge AI works — it does. The problem is that it cannot yet be managed in the same way as other production systems — and without that capability, deployment remains incomplete.